The First Node Done Right: How Lexikl's Request Node Makes Everything Click
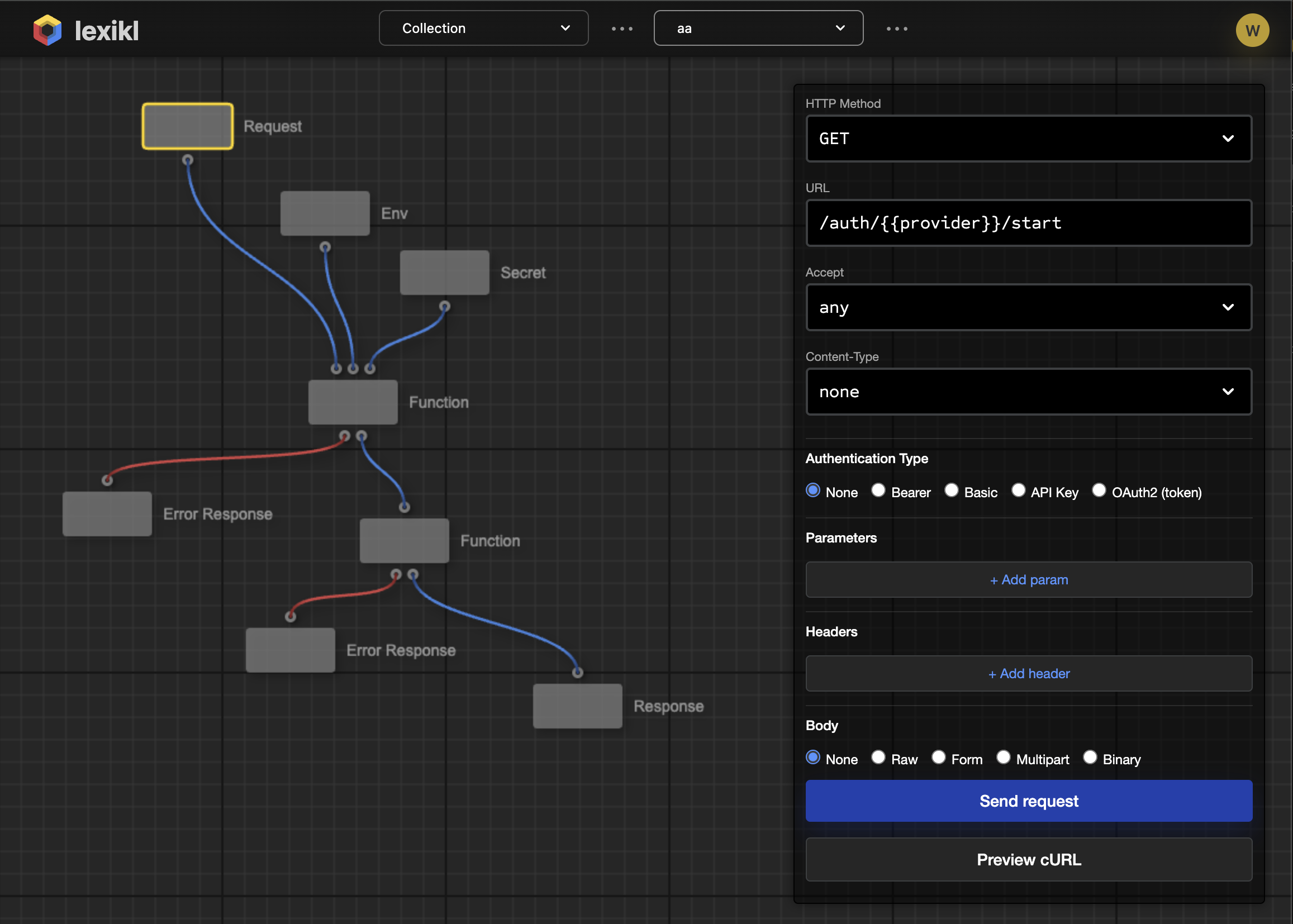
There's a moment in every platform's development when it suddenly clicks—when it goes from "interesting concept" to "oh, I get it!" For Lexikl, that moment happened when we built our first fully-featured node: the HTTP Request node. Not a simplified demo version. Not a proof-of-concept. A real, production-ready node with every feature you'd expect from tools like Postman or Insomnia.
The Difference Between Demo and Done
Early versions of Lexikl had nodes—simple ones that proved the concept. But they were abstractions. Placeholders. The kind of thing you'd show in a presentation with the caveat "imagine if this had all the features." When someone looked at the canvas, they had to imagine what it would be like to actually use.
The HTTP Request node changed that. Open it and you see:
- All 7 HTTP methods (GET, POST, PUT, DELETE, PATCH, HEAD, OPTIONS)
- Five authentication types (Bearer, Basic, API Key, OAuth2)
- Dynamic query parameters with add/remove functionality
- Custom headers configuration
- Multiple body types (Raw, Form, Multipart, Binary)
- Content-Type and Accept header quick-selects
- One-click cURL command generation
Suddenly, it's not a demo anymore. It's a tool. Anyone who's used an API client looks at this node and immediately understands what Lexikl is trying to be. No explanation needed. No "imagine if." It just works.
Instantly Understandable
This is the power of building things right. When you see a comprehensive HTTP request node connected to a data transformation node connected to a storage node, you don't need to read documentation. You can trace the flow: "It calls an API, processes the response, and saves it somewhere." The architecture is the documentation.
More importantly, you can inspect any step. What headers is it sending? What authentication is it using? What does the request body look like? Every detail is right there in the UI. No hidden configuration files. No magic environment variables. Everything explicit, everything visible.
This instant comprehensibility is exactly what you need when working with AI-generated code or reviewing someone else's workflow. The visual representation combined with comprehensive configuration means you can understand and trust the system at a glance.
The Swagger/OpenAPI Opportunity
Building this node unlocked something bigger than we initially realized: a clear path to automated workflow generation from API documentation. Think about it—a comprehensive HTTP request node is essentially a structured representation of an API call. And you know what else is a structured representation of API calls? Swagger/OpenAPI specifications.
Here's what becomes possible:
- Import Swagger Documentation: Drop in an OpenAPI spec and automatically generate request nodes for every endpoint
- Pre-configured Everything: Authentication schemes, required headers, request/response schemas—all automatically populated from the spec
- Type-Safe Connections: Nodes know their input and output types from the API documentation, preventing invalid connections
- Living Documentation: The workflow becomes a visual representation of how you're using an API, always in sync with your implementation
Imagine importing the Stripe API documentation and seeing dozens of pre-configured nodes for payments, customers, subscriptions, and webhooks. Or pulling in your internal microservices' OpenAPI specs and instantly having a palette of all available operations. No manual configuration. No reading docs to figure out authentication. It just works.
AI Fills in the Gaps
Now here's where it gets really interesting. Once you have nodes that perfectly represent API calls, you have inputs and outputs with well-defined schemas. You know what goes in, you know what comes out. The only thing missing is the logic in between.
That's where AI enters the picture. Imagine this workflow:
- Import Swagger: "I want to use the OpenAI API and the Slack API"
- Define Goal: "When someone mentions my product on Twitter, analyze the sentiment and post a summary to our #feedback channel"
-
AI Generates Workflow:
- Twitter webhook node (detects mentions)
- OpenAI sentiment analysis node (processes text)
- Transformation node (formats for Slack) ← AI writes this logic
- Slack post message node (sends notification)
The API nodes come from Swagger specs—pre-configured, type-safe, tested. The transformation logic between them? That's where AI shines. It sees the input schema (OpenAI response), the output schema (Slack message format), and your natural language description of what to do, and it generates the glue code.
If the generated code doesn't work, AI can see the error, understand the schemas, and try again. The visual representation means you can watch it happen, inspect each step, and intervene if needed. You're not trusting a black box—you're supervising an assistant.
From Node to Ecosystem
This is why getting the first node right matters so much. It's not just about having a working HTTP client. It's about establishing the pattern for everything that comes next:
- Database nodes: Connect to PostgreSQL, MongoDB, Redis with full query builders
- Cloud service nodes: S3 upload, SQS queues, DynamoDB operations—all pre-configured
- AI service nodes: OpenAI, Anthropic, Cohere—standardized interfaces for model interactions
- Transformation nodes: JSON parsing, data validation, format conversion—AI-generated to match your needs
- Logic nodes: Conditionals, loops, error handling—visual control flow that compiles to production code
Each category can be populated from existing standards. Swagger for APIs. Database schema introspection for data operations. Cloud service SDKs for infrastructure. The node structure we established with the HTTP request becomes a template that works everywhere.
The Technical Foundation
Building this properly required some careful architecture decisions. The form system needed to be:
- Type-safe: TypeScript interfaces for every field type
- Extensible: New field types (like key-value lists) without rewriting the renderer
- Conditional: Radio buttons that show/hide relevant fields
- Compact: Scrollable forms that don't overwhelm the interface
- Serializable: Everything captured in JSON for saving and sharing
We now have a form schema system that can represent any configuration interface. When we import a Swagger spec, we can programmatically generate these forms. When AI creates a transformation node, it can define the configuration UI. The pattern scales.
What This Means for Developers
If you're a developer building with APIs (and who isn't?), this changes your workflow:
Before: Read API docs → Write code → Debug authentication → Handle errors → Parse responses → Transform data → Repeat for every endpoint
After: Import Swagger → Drag nodes onto canvas → Describe what you want → AI generates transformation logic → Test visually → Deploy to production
The tedious parts (API configuration, authentication, error handling) are handled by pre-built nodes. The creative parts (business logic, data transformations) are assisted by AI but fully visible and editable by you. The result is code you can understand, modify, and trust.
The Road Ahead
Getting this first node right was just the beginning. It proved that visual scripting can handle real complexity. It showed that comprehensive configuration doesn't have to mean cluttered interfaces. And it revealed a path forward where API documentation becomes workflow scaffolding, and AI becomes the assistant that fills in the gaps.
We're now building the Swagger import system. Next comes AI-assisted node generation. Then the node marketplace where you can share and monetize the workflows you've built. Each piece builds on this foundation: comprehensive, understandable, production-ready nodes that just work.
The future of development isn't about writing less code—it's about making the code you do write more understandable, more maintainable, and more powerful. That starts with getting the fundamentals right. Starting with building nodes that don't need explanation because they're exactly what you expect them to be.
Try It Yourself
The HTTP request node is live at lexikl.com. Create a workflow, add a request node, and configure an API call. See how quickly you can go from idea to working integration. No setup, no installation, no configuration hell. Just nodes that work.
And if you're excited about the Swagger integration possibilities, join our community. We're building this in the open, and the best ideas come from developers who see what's possible and push us to make it real.
The first node is done right. Now we're ready to build the rest of the ecosystem.